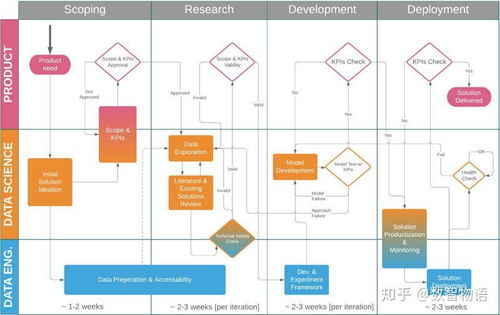
随着金融行业的数字化发展,数据科学在金融知识流程外包(Knowledge Process Outsourcing, KPO)中的应用日益广泛。启动一个成功的数据科学项目需要系统的规划和执行,尤其是在金融领域,其中涉及的数据敏感性和复杂性较高。本文将介绍如何从零开始启动一个数据科学项目,专注于金融知识流程外包环境,涵盖关键步骤、工具和最佳实践。
一、明确项目目标和范围
在项目启动前,必须清晰定义业务目标。金融知识流程外包通常涉及风险管理、客户分析、投资组合优化或合规性检查等任务。例如,如果目标是通过数据科学改进信用风险评估,需确定具体指标,如减少违约率或提高预测准确度。与利益相关者(如金融专家、外包客户)沟通,确保项目范围明确,避免后续范围蔓延。关键问题包括:项目要解决什么金融问题?预期成果是什么?数据来源和可用性如何?
二、数据收集与预处理
数据是数据科学项目的核心。在金融KPO中,数据可能来自内部数据库、公开市场数据或客户提供的第三方数据源。识别相关数据,如交易记录、财务报表或市场指数。接着,进行数据清洗,处理缺失值、异常值和重复数据,以确保数据质量。金融数据常涉及时间序列,需注意时间对齐和标准化。使用工具如Python(Pandas库)或SQL进行预处理,并确保遵守数据隐私法规(如GDPR或金融行业规范)。
三、构建数据科学团队和基础设施
一个有效的团队是项目成功的关键。在金融KPO环境中,团队应包括数据科学家、金融分析师、领域专家和项目经理。明确角色分工:数据科学家负责模型开发,金融专家提供行业洞察,项目经理协调资源和时间线。同时,建立技术基础设施,如云平台(AWS或Azure)用于数据存储和计算,版本控制工具(Git)管理代码,并采用敏捷方法进行迭代开发。金融项目往往需要高安全性和合规性,因此需部署加密和访问控制机制。
四、模型开发与验证
基于预处理的数据,开始构建和训练模型。根据项目目标,选择合适算法,例如回归模型用于预测股价,分类模型用于欺诈检测,或聚类分析用于客户细分。在金融领域,模型需具备可解释性和稳健性,避免黑箱问题。使用交叉验证和回测技术评估模型性能,确保在历史数据上表现良好。验证过程应与金融专家协作,检查模型是否符合行业逻辑和监管要求。工具如Scikit-learn、TensorFlow或专用金融库(如QuantLib)可加速开发。
五、部署与监控
模型开发完成后,部署到生产环境中,以供金融KPO客户使用。这可以是API接口、仪表板或集成到现有系统。部署后,持续监控模型性能,检测数据漂移或概念漂移,及时调整模型。金融市场的动态性要求定期更新数据和重新训练模型。同时,建立反馈机制,收集用户输入以改进解决方案。项目收尾时,文档化整个过程,包括数据流水线、模型参数和业务影响,便于知识转移和外包协作。
六、总结与最佳实践
启动一个数据科学项目在金融KPO中需要跨学科协作和严格流程。关键成功因素包括:明确目标、高质量数据、团队协作、持续监控和合规性管理。建议从小型试点项目开始,逐步扩展,以降低风险。通过这种方式,数据科学可以显著提升金融外包服务的效率和价值,例如通过自动化报告生成或增强决策支持。最终,项目应聚焦于交付可衡量的业务成果,从而巩固客户关系和竞争优势。